Mapping¶
In essence, an Elasticsearch index is mapped to a Cassandra keyspace, and a document type to a Cassandra table.
Type mapping¶
Below is the mapping from Elasticsearch field basic types to CQL3 types :
| Elasticearch Types | CQL Types | Comment |
|---|---|---|
| keyword | text | Not analyzed text |
| text | text | Analyzed text |
| date | timestamp | |
| date | date | Existing Cassandra date columns mapped to an Elasticsearch date. (32-bit integer representing days since epoch, January 1, 1970) |
| byte | tinyint | |
| short | smallint | |
| integer | int | |
| long | bigint | |
| keyword | decimal | Existing Cassandra decimal columns are mapped to an Elasticsearch keyword. |
| long | time | Existing Cassandra time columns (64-bit signed integer representing the number of nanoseconds since midnight) stored as long in Elasticsearch. |
| double | double | |
| float | float | |
| boolean | boolean | |
| binary | blob | |
| ip | inet | Internet address |
| keyword | uuid | Existing Cassandra uuid columns are mapped to an Elasticsearch keyword. |
| keyword or date | timeuuid | Existing Cassandra timeuuid columns are mapped to an Elasticsearch keyword by default, or can explicitly be mapped to an Elasticsearch date. |
| geo_point | UDT geo_point or text | Built-In User Defined Type (1) |
| geo_shape | text | Requires _source enabled (2) |
| range | UDT xxxx_range | Elasticsearch range (integer_range, float_range, long_range, double_range, date_range, ip_range) |
| object, nested | Custom User Defined Type | User Defined Type should be frozen, as described in the Cassandra documentation. |
- Geo shapes require _source to be enabled to store the original JSON document (default is disabled).
- Existing Cassandra text columns containing a geohash string can be mapped to an Elasticsearch geo_point.
CQL mapper extensions¶
Elassandra adds some Elasticsearch mapper extensions in order to map Elasticsearch field to Cassandra:
| Parameter | Values | Description |
|---|---|---|
cql_collection |
list, set, singleton or none | Control how the field of type X is mapped to a column list<X>, set<X> or X. Default is list because Elasticsearch fields are multivalued. For copyTo fields, none means the field is not backed into Cassandra but just indexed by Elasticsearch. |
cql_struct |
udt, map or opaque_map | Control how an object or nested field is mapped to a User Defined Type or to a Cassandra. When using map, each new key is registred as a subfield in the elasticsearch mapping through a mapping update request. When using opaque_map, each new key is silently indexed as a new field, but the elasticsearch mapping is not updated. |
cql_static_column |
true or false | When true, the underlying CQL column is static. Default is false. |
cql_primary_key_order |
integer | Field position in the Cassandra the primary key of the underlying Cassandra table. Default is -1 meaning that the field is not part of the Cassandra primary key. |
cql_partition_key |
true or false | When the cql_primary_key_order >= 0, specify if the field is part of the Cassandra partition key. Default is false meaning that the field is not part of the Cassandra partition key. |
cql_clustering_key_desc |
true or false | Indicates if the field is a clustering key in ascending or descending order, default is ascending (false). See Cassandra documentation about clustering key ordering. |
cql_udt_name |
<table_name>_<field_name> | Specify the Cassandra User Defined Type name to use to store an object. By default, this is automatically build (dots in field_names are replaced by underscores) |
cql_type |
<CQL type> | Specify the Cassandra type to use to store an elasticsearch field. By default, this is automatically set depending on the Elasticsearch field type, but in some situation, you can overwrite the default type by another one. |
For more information about Cassandra collection types and compound primary key, see CQL Collections and Compound keys.
Tip
For every update, Elassandra reads for missing fields in order to build a full Elasticsearch document. If some fields are backed by Cassandra collections (map, set or list), Elassandra force a read before index even if all fields are provided in the Cassandra upsert operation. For this reason, when you don’t need multi-valued fields, use fields backed by native Cassandra types rather than the default list to avoid a read-before-index when inserting a row containing all its mandatory elasticsearch fields.
Elasticsearch multi-fields¶
Elassandra supports Elasticsearch multi-fields <https://www.elastic.co/guide/en/elasticsearch/reference/6.2/multi-fields.html> indexing, allowing to index a field in many ways for different purposes.
Tip
Indexing a wrong datatype into a field may throws an exception by default and reject the whole document. The ignore_malformed parameter, if set to true, allows the exception to be ignored. This parameter can also be set at the index level, to allow to ignore malformed content globally across all mapping types.
Bi-directional mapping¶
Elassandra supports the Elasticsearch Indice API and automatically creates the underlying Cassandra keyspaces and tables. For each Elasticsearch document type, a Cassandra table is created to reflect the Elasticsearch mapping. However, deleting an index does not remove the underlying keyspace, it only removes the Cassandra secondary indices associated to the mapped columns.
Additionally, with the new put mapping parameter discover, Elassandra creates or updates the Elasticsearch mapping for an existing Cassandra table.
Columns matching the provided regular expression are mapped as Elasticsearch fields. The following command creates the Elasticsearch mapping for all columns starting with a ‘a’ in the Cassandra table my_keyspace.my_table and set a specific analyser for column name.
curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/my_keyspace/_mapping/my_table" -d '{
"my_table" : {
"discover" : "a.*",
"properties" : {
"name" : {
"type" : "text"
}
}
}
}'
By default, all text columns are mapped with "type":"keyword". Moreover, the discovery regular expression must exclude explicitly mapped fields to avoid inconsistent mapping.
The following mapping update allows to discover all fields but the one named “name” and explicitly define its mapping.
curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/my_keyspace/_mapping/my_table" -d '{
"my_table" : {
"discover" : "^((?!name).*)",
"properties" : {
"name" : {
"type" : "text"
}
}
}
}'
Tip
When creating the first Elasticsearch index for a given Cassandra table, Elassandra creates a custom CQL secondary index. Cassandra automatically builds indices on all nodes for all existing data. Subsequent CQL inserts or updates are automatically indexed in Elasticsearch.
If you then add a second or additional Elasticsearch indices to an existing indexed table, existing data are not automatically re-indexed because Cassandra has already indexed existing data. Instead of re-inserting your data into the Cassandra table, you may want to use the following command to force a Cassandra index rebuild. It will re-index your Cassandra table to all associated Elasticsearch indices :
nodetool rebuild_index --threads <N> <keyspace_name> <table_name> elastic_<table_name>_idx
- rebuild_index reindexes SSTables from disk, but not from MEMtables. In order to index the very last inserted document, run a nodetool flush <kespace_name> before rebuilding your Elasticsearch indices.
- When deleting an elasticsearch index, elasticsearch index files are removed from the data/elasticsearch.data directory, but the Cassandra secondary index remains in the CQL schema until the last associated elasticsearch index is removed. Cassandra is acting as primary data storage, so keyspace and tables and data are never removed when deleting an elasticsearch index.
Meta-Fields¶
Elasticsearch meta-fields meaning is slightly different in Elassandra :
_indexis the index name mapped to the underlying Cassandra keyspace name (dash [-] and dot[.] are automatically replaced by underscore [_])._typeis the document type name mapped to the underlying Cassandra table name (dash [-] and dot[.] are automatically replaced by underscore [_]). Since Elasticsearch 6.x, there is only one type per index._idis the document ID is a string representation of the primary key of the underlying Cassandra table. Single field primary key is converted to a string, compound primary key is converted into a JSON array converted to a string. For example, if your primary key is a string and a number, you will get_id= [“003011FAEF2E”,1493502420000]. To get such a document by its_id, you need to properly escape brackets and double-quotes as shown below.
get 'twitter/tweet/\["003011FAEF2E",1493502420000\]?pretty'
{
"_index" : "twitter",
"_type" : "tweet",
"_id" : "[\"003011FAEF2E\",1493502420000]",
"_version" : 1,
"found" : true,
"_source" : {
...
}
}
_sourceis the indexed JSON document. By default, _source is disabled in Elassandra, meaning that _source is rebuild from the underlying Cassandra columns. If _source is enabled (see Mapping _source field) ELassandra stores documents indexed by with the Elasticsearch API in a dedicated Cassandra text column named _source. This allows to retreive the orginal JSON document for GeoShape Query._routingis valued with a string representation of the partition key of the underlying Cassandra table. Single partition key is converted into a string, compound partition key is converted into a JSON array. Specifying_routingon get, index or delete operations is useless, since the partition key is included in_id. On search operations, Elassandra computes the Cassandra token associated with_routingfor the search type, and reduces the search only to a Cassandra node hosting the token. (WARNING: Without any search types, Elassandra cannot compute the Cassandra token and returns with an error all shards failed)._ttland_timestampare mapped to the Cassandra TTL and WRITIME in Elassandra 5.x. The returned_ttland_timestampfor a document will be the one of a regular Cassandra column if there is one in the underlying table. Moreover, when indexing a document through the Elasticsearch API, all Cassandra cells carry the same WRITETIME and TTL, but this could be different when upserting some cells using CQL._parentis string representation of the parent document primary key. If the parent document primary key is composite, this is string representation of columns defined bycql_parent_pkin the mapping. See Parent-Child Relationship._tokenis a meta-field introduced by Elassandra, valued with token(<partition_key>)._hostis an optional meta-field introduced by Elassandra, valued with the Cassandra host id, allowing to check the datacenter consistency.
Mapping change with zero downtime¶
You can map several Elasticsearch indices with different mappings to the same Cassandra keyspace.
By default, an index is mapped to a keyspace with the same name, but you can specify a target keyspace in your index settings.
For example, you can create a new index twitter2 mapped to the Cassandra keyspace twitter and set a mapping for the type tweet associated to the existing Cassandra table twitter.tweet.

curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/twitter2/" -d '{
"settings" : { "keyspace" : "twitter" } },
"mappings" : {
"tweet" : {
"properties" : {
"message" : { "type" : "text" },
"post_date" : { "type" : "date", "format": "yyyy-MM-dd" },
"user" : { "type" : "keyword" },
"size" : { "type" : "long" }
}
}
}
}
You can set a specific mapping for twitter2 and re-index existing data on each Cassandra node with the following command (indices are named elastic_<tablename>_idx).
nodetool rebuild_index [--threads <N>] twitter tweet elastic_tweet_idx
By default, rebuild_index uses only one thread, but Elassandra supports multi-threaded index rebuild with the new parameter –threads. Index name is <elastic>_<table_name>_idx where column_name is any indexed column name. Once your twitter2 index is ready, set an alias twitter for twitter2 to switch from the old mapping to the new one, and delete the old twitter index.
curl -XPOST -H 'Content-Type: application/json' "http://localhost:9200/_aliases" -d '{ "actions" : [ { "add" : { "index" : "twitter2", "alias" : "twitter" } } ] }'
curl -XDELETE "http://localhost:9200/twitter"
Partitioned Index¶
Elasticsearch TTL support is deprecated since Elasticsearch 2.0 and the Elasticsearch TTLService is disabled in Elassandra. Rather than periodically looking for expired documents, Elassandra supports partitioned index allowing managing per time-frame indices. Thus, old data can be removed by simply deleting old indices.
Partitioned index also allows indexing more than 2^31 documents on a node (2^31 is the lucene max documents per index).
An index partition function acts as a selector when many indices are associated to a Cassandra table. A partition function is defined by 3 or more fields separated by a space character :
- Function name.
- Index name pattern.
- 1 to N document field names.
The target index name is the result your partition function,
A partition function must implements the java interface org.elassandra.index.PartitionFunction. Two implementation classes are provided :
- StringFormatPartitionFunction (the default) based on the JDK function String.format(Locale locale, <parttern>,<arg1>,…).
- MessageFormatPartitionFunction based on the JDK function MessageFormat.format(<parttern>,<arg1>,…).
- TimeUUIDPartitionFunction based on the JDK function String.format(Locale locale, <parttern>,<arg1>,…) (A TimeUUID argument will be converted as java.lang.Date).
Index partition function are stored in a map, so a given index function is executed exactly once for all mapped index. For example, the toYearIndex function generates the target index logs_<year> depending on the value of the date_field for each document (or row).
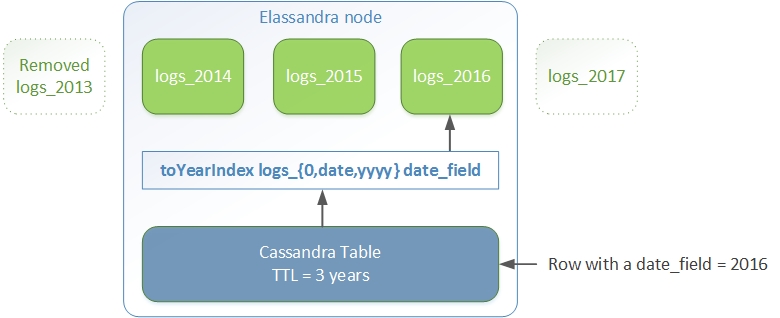
You can define each per-year index as follow, with the same index.partition_function for all logs_<year>.
All these indices will be mapped to the keyspace logs, and all columns of the table mylog automatically mapped to the document type mylog.
curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/logs_2016" -d '{
"settings": {
"keyspace":"logs",
"index.partition_function":"toYearIndex logs_{0,date,yyyy} date_field",
"index.partition_function_class":"MessageFormatPartitionFunction"
},
"mappings": {
"mylog" : { "discover" : ".*" }
}
}'
Tip
Partition function is executed for each indexed document, so if write throughput is a concern, you should choose an efficient implementation class.
How To remove an old index.
curl -XDELETE "http://localhost:9200/logs_2013"
Cassandra TTL can be used in conjunction with partitioned index to automatically removed rows during the normal Cassandra compaction and repair processes when index_on_compaction is true, however it introduces a Lucene merge overhead because the document are re-indexed when compacting. You can also use the DateTieredCompactionStrategy to the TimeWindowTieredCompactionStrategy to improve performance of time series-like workloads.
Virtual index¶
In conjunction with partitioned indices, you can use a virtual index to share the same mapping for all partitioned indices.
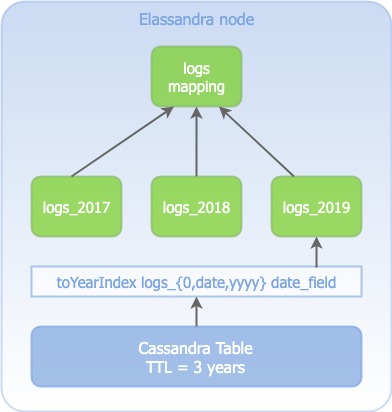
A newly created index inherits the mapping created for other partitioned indices, and this drastically reduce the volume of Elasticsearch mappings stored in the CQL schema, and the number of mapping update across the cluster.
In order to create a partitioned index using the mapping of the virtual index, just add the name of the virtual index name as show bellow.
curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/logs_2016" -d '{
"settings": {
"keyspace":"logs",
"index.partition_function":"toYearIndex logs_{0,date,yyyy} date_field",
"index.partition_function_class":"MessageFormatPartitionFunction",
"index.virtual_index":"logs"
},
"mappings": {
"mylog" : { "discover" : ".*" }
}
}'
The mappings section is only used to create the virtual index logs if it not exists when logs_2016 is created.
This virtual index logs have (or must have if you create it explicitly) the settings index.virtual=true and it will always be empty.
Moreover, index templates can be used to specify common settings between partitioned index, including the virtual index name and its default mapping.
Object and Nested mapping¶
By default, Elasticsearch Object or nested types are mapped to dynamically created Cassandra User Defined Types.
curl -XPUT -H 'Content-Type: application/json' 'http://localhost:9200/twitter/tweet/1' -d '{
"user" : {
"name" : {
"first_name" : "Vincent",
"last_name" : "Royer"
},
"uid" : "12345"
},
"message" : "This is a tweet!"
}'
curl -XGET 'http://localhost:9200/twitter/tweet/1/_source'
{"message":"This is a tweet!","user":{"uid":["12345"],"name":[{"first_name":["Vincent"],"last_name":["Royer"]}]}}
The resulting Cassandra user defined types and table.
cqlsh>describe keyspace twitter;
CREATE TYPE twitter.tweet_user (
name frozen<list<frozen<tweet_user_name>>>,
uid frozen<list<text>>
);
CREATE TYPE twitter.tweet_user_name (
last_name frozen<list<text>>,
first_name frozen<list<text>>
);
CREATE TABLE twitter.tweet (
"_id" text PRIMARY KEY,
message list<text>,
person list<frozen<tweet_person>>
)
cqlsh> select * from twitter.tweet;
_id | message | user
-----+----------------------+-----------------------------------------------------------------------------
1 | ['This is a tweet!'] | [{name: [{last_name: ['Royer'], first_name: ['Vincent']}], uid: ['12345']}]
Dynamic mapping of Cassandra Map¶
By default, nested document are be mapped to User Defined Type. For top level fields only, you can also use a CQL map having a text key and a value of native or UDT type (using a collection in a map is not supported by Cassandra).
With cql_struct=map, each new key in the map involves an Elasticsearch mapping update (and a PAXOS transaction) to declare the key as a new field.
Obviously, don’t use such mapping when keys are versatile.
With cql_struct=opaque_map, Elassandra silently index each key as an Elasticsearch field, but does not update the mapping, which is far more efficient when using versatile keys.
Every sub-fields (or every entry in the map) have the same type defined by the pseudo field name _key in the mapping.
These fields are searchable, except with query string queries
because Elasticsearch cannot lookup fields in the mapping.
Finally, when discovering the mapping from the CQL schema, Cassandra maps columns are mapped to an opaque_map by default. Adding explicit sub-fields to
an opaque_map is still possible if you need to make these fields visible to Kibana for example.
In the following example, each new key entry in the map attrs is mapped as field.
CREATE KEYSPACE IF NOT EXISTS twitter WITH replication={ 'class':'NetworkTopologyStrategy', 'DC1':'1' };
CREATE TABLE twitter.user (
name text,
attrs map<text,text>,
PRIMARY KEY (name)
);
INSERT INTO twitter.user (name,attrs) VALUES ('bob',{'email':'bob@gmail.com','firstname':'bob'});
Create the type mapping from the Cassandra table and search for the bob entry.
curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/twitter" -d '{
"mappings": {
"user" : { "discover" : "^((?!attrs).*)" }
}
}'
curl -XPUT -H 'Content-Type: application/json' 'http://localhost:9200/twitter/_mapping/user?pretty=true' -d'{
"properties" : {
"attrs" : {
"type" : "nested",
"cql_struct" : "map",
"cql_collection" : "singleton",
"properties" : {
"email" : {
"type" : "keyword"
},
"firstname" : {
"type" : "keyword"
}
}
}
}
}'
curl -XGET "http://localhost:9200/twitter/user/bob?pretty=true"
{
"_index" : "twitter",
"_type" : "user",
"_id" : "bob",
"_version" : 0,
"found" : true,
"_source":{"name":"bob","attrs":{"email":"bob@gmail.com","firstname":"bob"}}
}
Now insert a new entry in the attrs map column and search for a nested field attrs.city:paris.
UPDATE twitter.user SET attrs = attrs + { 'city':'paris' } WHERE name = 'bob';
curl -XGET -H 'Content-Type: application/json' "http://localhost:9200/twitter/_search?pretty=true" -d '{
"query":{
"nested":{
"path":"attrs",
"query":{ "term": {"attrs.city":"paris" } }
}
}
}'
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 2.3862944,
"hits" : [ {
"_index" : "twitter",
"_type" : "user",
"_id" : "bob",
"_score" : 2.3862944,
"_source":{"attrs":{"city":"paris","email":"bob@gmail.com","firstname":"bob"},"name":"bob"}
} ]
}
}
With an opaque_map, search results are the same, and the Elasticsearch mapping is:
curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/twitter" -d '{
"mappings": {
"user" : { "discover" : ".*" }
}
}'
curl -XGET "http://localhost:9200/twitter?pretty"
{
"twitter" : {
"aliases" : { },
"mappings" : {
"user" : {
"properties" : {
"attrs" : {
"type" : "nested",
"cql_struct" : "opaque_map",
"cql_collection" : "singleton",
"properties" : {
"_key" : {
"type" : "keyword",
"cql_collection" : "singleton"
}
}
},
"name" : {
"type" : "keyword",
"cql_collection" : "singleton",
"cql_partition_key" : true,
"cql_primary_key_order" : 0
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1568060813134",
"number_of_shards" : "1",
"number_of_replicas" : "0",
"uuid" : "ZyolrbP9Qjm8rNezne7wUw",
"version" : {
"created" : "6020399"
},
"provided_name" : "twitter"
}
}
}
}
Dynamic Template with Dynamic Mapping¶
Dynamic templates can be used when creating a dynamic field from a Cassandra map.
"mappings" : {
"event_test" : {
"dynamic_templates": [ {
"strings_template": {
"match": "strings.*",
"mapping": {
"type": "keyword"
}
}
} ],
"properties" : {
"id" : {
"type" : "keyword",
"cql_collection" : "singleton",
"cql_partition_key" : true,
"cql_primary_key_order" : 0
},
"strings" : {
"type" : "object",
"cql_struct" : "map",
"cql_collection" : "singleton"
}
}
}
}
A new entry key1 in the underlying Cassandra map will have the following mapping:
"mappings" : {
"event_test" : {
"dynamic_templates" : [ {
"strings_template" : {
"mapping" : {
"type" : "keyword",
"doc_values" : true
},
"match" : "strings.*"
}
} ],
"properties" : {
"strings" : {
"cql_struct" : "map",
"cql_collection" : "singleton",
"type" : "nested",
"properties" : {
"key1" : {
"type" : "keyword"
}
},
"id" : {
"type" : "keyword",
"cql_partition_key" : true,
"cql_primary_key_order" : 0,
"cql_collection" : "singleton"
}
}
}
}
Note that because doc_values is true by default for a keyword field, it does not appear in the mapping.
Parent-Child Relationship¶
Warning
Parent child is supported in Elassandra 5.x.
Elassandra supports parent-child relationship when parent and child documents are located on the same Cassandra node. This condition is met :
- when running a single node cluster,
- when the keyspace replication factor equals the number of nodes or
- when the parent and child documents share the same Cassandra partition key, as shown in the following example.
Create an index company (a Cassandra keyspace), a Cassandra table, insert 2 rows and map this table as document type employee.
cqlsh <<EOF
CREATE KEYSPACE IF NOT EXISTS company WITH replication={ 'class':'NetworkTopologyStrategy', 'dc1':'1' };
CREATE TABLE company.employee (
"_parent" text,
"_id" text,
name text,
dob timestamp,
hobby text,
primary key (("_parent"),"_id")
);
INSERT INTO company.employee ("_parent","_id",name,dob,hobby) VALUES ('london','1','Alice Smith','1970-10-24','hiking');
INSERT INTO company.employee ("_parent","_id",name,dob,hobby) VALUES ('london','2','Alice Smith','1990-10-24','hiking');
EOF
curl -XPUT -H 'Content-Type: application/json' "http://$NODE:9200/company2" -d '{
"mappings" : {
"employee" : {
"discover" : ".*",
"_parent" : { "type": "branch", "cql_parent_pk":"branch" }
}
}
}'
curl -XPOST -H 'Content-Type: application/json' "http://127.0.0.1:9200/company/branch/_bulk" -d '
{ "index": { "_id": "london" }}
{ "district": "London Westminster", "city": "London", "country": "UK" }
{ "index": { "_id": "liverpool" }}
{ "district": "Liverpool Central", "city": "Liverpool", "country": "UK" }
{ "index": { "_id": "paris" }}
{ "district": "Champs Élysées", "city": "Paris", "country": "France" }
'
Search for documents having children document of type employee with dob date greater than 1980.
curl -XGET "http://$NODE:9200/company2/branch/_search?pretty=true" -d '{
"query": {
"has_child": {
"type": "employee",
"query": {
"range": {
"dob": {
"gte": "1980-01-01"
}
}
}
}
}
}'
Search for employee documents having a parent document where country match UK.
curl -XGET "http://$NODE:9200/company2/employee/_search?pretty=true" -d '{
"query": {
"has_parent": {
"parent_type": "branch",
"query": {
"match": { "country": "UK"
}
}
}
}
}'
Indexing Cassandra static columns¶
When a Cassandra table has one or more clustering columns, a static columns is shared by all the rows with the same partition key.
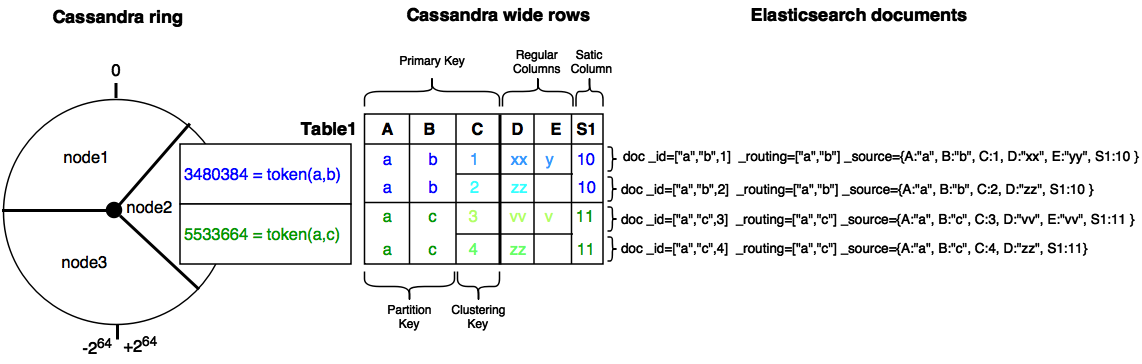
Each time a static columns is modified, a document containing the partition key and only static columns is indexed in Elasticserach. By default, static columns are not indexed with every wide rows because any update on a static column would requires reindexation of all wide rows. However, you can request for fields backed by a static column on any get/search request.
The following example demonstrates how to use static columns to store meta information of a timeserie.
curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/test" -d '{
"mappings" : {
"timeseries" : {
"properties" : {
"t" : {
"type" : "date",
"format" : "strict_date_optional_time||epoch_millis",
"cql_primary_key_order" : 1,
"cql_collection" : "singleton"
},
"meta" : {
"type" : "nested",
"cql_struct" : "map",
"cql_static_column" : true,
"cql_collection" : "singleton",
"include_in_parent" : true,
"index_static_document": true,
"index_static_columns": true,
"properties" : {
"region" : {
"type" : "keyword"
}
}
},
"v" : {
"type" : "double",
"cql_collection" : "singleton"
},
"m" : {
"type" : "keyword",
"cql_partition_key" : true,
"cql_primary_key_order" : 0,
"cql_collection" : "singleton"
}
}
}
}
}'
cqlsh <<EOF
INSERT INTO test.timeseries (m, t, v) VALUES ('server1-cpu', '2016-04-10 13:30', 10);
INSERT INTO test.timeseries (m, t, v) VALUES ('server1-cpu', '2016-04-10 13:31', 20);
INSERT INTO test.timeseries (m, t, v) VALUES ('server1-cpu', '2016-04-10 13:32', 15);
INSERT INTO test.timeseries (m, meta) VALUES ('server1-cpu', { 'region':'west' } );
SELECT * FROM test.timeseries;
EOF
m | t | meta | v
-------------+-----------------------------+--------------------+----
server1-cpu | 2016-04-10 11:30:00.000000z | {'region': 'west'} | 10
server1-cpu | 2016-04-10 11:31:00.000000z | {'region': 'west'} | 20
server1-cpu | 2016-04-10 11:32:00.000000z | {'region': 'west'} | 15
Search for wide rows only where v=10 and fetch the meta.region field.
curl -XGET "http://localhost:9200/test/timeseries/_search?pretty=true&q=v:10&fields=m,t,v,meta.region,_source"
"hits" : [ {
"_index" : "test",
"_type" : "timeseries",
"_id" : "[\"server1-cpu\",1460287800000]",
"_score" : 1.9162908,
"_routing" : "server1-cpu",
"_source" : {
"t" : "2016-04-10T11:30:00.000Z",
"v" : 10.0,
"meta" : { "region" : "west" },
"m" : "server1-cpu"
},
"fields" : {
"meta.region" : [ "west" ],
"t" : [ "2016-04-10T11:30:00.000Z" ],
"m" : [ "server1-cpu" ],
"v" : [ 10.0 ]
}
} ]
Search for rows where meta.region=west, returns only a static document (i.e. document containing the partition key and static columns) because index_static_document is true.
curl -XGET "http://localhost:9200/test/timeseries/_search?pretty=true&q=meta.region:west&fields=m,t,v,meta.region"
"hits" : {
"total" : 1,
"max_score" : 1.5108256,
"hits" : [ {
"_index" : "test",
"_type" : "timeseries",
"_id" : "server1-cpu",
"_score" : 1.5108256,
"_routing" : "server1-cpu",
"fields" : {
"m" : [ "server1-cpu" ],
"meta.region" : [ "west" ]
}
} ]
If needed, you can change the default behavior for a specific Cassandra table (or elasticsearch document type), by using the following custom metadata :
index_static_documentcontrols whether or not static document (i.e. document containing the partition key and static columns) are indexed (default is false).index_static_onlyif true, it only indexes static documents with partition key as_idand static columns as fields.index_static_columnscontrols whether or not static columns are included in the indexed documents (default is false).
Be careful, if index_static_document = false and index_static_only = true, it will not index any document. In our example with the following mapping, static columns are indexed in every document, allowing to search on.
curl -XPUT -H 'Content-Type: application/json' http://localhost:9200/test/_mapping/timeseries -d '{
"timeseries": {
"discover" : ".*",
"_meta": {
"index_static_document":true,
"index_static_columns":true
}
}
}'
Elassandra as a JSON-REST Gateway¶
When dynamic mapping is disabled and a mapping type has no indexed field, elassandra nodes can act as a JSON-REST gateway for Cassandra to get, set or delete a Cassandra row without any indexing overhead. In this case, the mapping may be use to cast types or format date fields, as shown below.
CREATE TABLE twitter.tweet (
"_id" text PRIMARY KEY,
message list<text>,
post_date list<timestamp>,
size list<bigint>,
user list<text>
)
curl -XPUT -H 'Content-Type: application/json' "http://$NODE:9200/twitter/" -d'{
"settings":{ "index.mapper.dynamic":false },
"mappings":{
"tweet":{
"properties":{
"size": { "type":"long", "index":"no" },
"post_date":{ "type":"date", "index":"no", "format" : "strict_date_optional_time||epoch_millis" }
}
}
}
}'
As a result, you can index, get or delete a Cassandra row, including any column from your Cassandra table.
curl -XPUT -H 'Content-Type: application/json' "http://localhost:9200/twitter/tweet/1?consistency=one" -d '{
"user" : "vince",
"post_date" : "2009-11-15T14:12:12",
"message" : "look at Elassandra !!",
"size": 50
}'
{"_index":"twitter","_type":"tweet","_id":"1","_version":1,"_shards":{"total":1,"successful":1,"failed":0},"created":true}
$ curl -XGET "http://localhost:9200/twitter/tweet/1?pretty=true&fields=message,user,size,post_date'
{
"_index" : "twitter",
"_type" : "tweet",
"_id" : "1",
"_version" : 1,
"found" : true,
"fields" : {
"size" : [ 50 ],
"post_date" : [ "2009-11-15T14:12:12.000Z" ],
"message" : [ "look at Elassandra !!" ],
"user" : [ "vince" ]
}
}
$ curl -XDELETE "http://localhost:9200/twitter/tweet/1?pretty=true'
{
"found" : true,
"_index" : "twitter",
"_type" : "tweet",
"_id" : "1",
"_version" : 0,
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
}
}
Elasticsearch pipeline processors¶
Elassandra 6.x supports Elasticsearch pipeline processors when indexing through the Elasticsearch API. The following example illustrates how to generates a timeuuid clustering key when ingesting some logs into Elassandra (requires Elassandra 6.2.3.8+):
First, create a named pipeline as show below. This pipeline adds a new timeuuid field based on the existing date field es_time using the date format ISO8601 in europ timezone.
The second processor set the document _id to a JSON compound key including the field kubernetes.docker_id (as the Cassandra partition key) and ts as a clustering key with CQL type timeuuid.
curl -H "Content-Type: application/json" -XPUT "http://localhost:9200/_ingest/pipeline/fluentbit" -d'
{
"description" : "fluentbit elassandra pipeline",
"processors" : [
{
"timeuuid" : {
"field": "es_time",
"target_field": "ts",
"formats" : ["ISO8601"],
"timezone" : "Europe/Amsterdam"
}
},
{
"set" : {
"field": "_id",
"value": "[\"{{kubernetes.docker_id}}\",\"{{ts}}\"]"
}
}
]
}'
Because timeuuid is not an Elasticsearch type, this CQL type must be explicit in the Elasticsearch mapping using the cql_type field mapping attribute to replace the default timestamp by timeuuid. This can be acheived with an elasticsearch template.
Your mapping must also defines a Cassandra partition key as text, and a clustering key of type timeuuid.
Check Cassandra consistency with Elasticsearch¶
When the index.include_host = true (default is false), the _host metafield containing the Cassandra host id is included in every indexed document.
This allows distinguishing multiple copies of a document when the datacenter replication factor is greater than one. Then a token range aggregation allows counting the number of documents for each token range and for each Cassandra node.
In the following example, we have 1000 accounts documents in a keyspace with RF=2 in a two nodes datacenter, with each token ranges having the same number of document for the two nodes.
curl -XGET "http://$NODE:9200/accounts/_search?pretty=true&size=0" -d'{
"aggs" : {
"tokens" : {
"token_range" : {
"field" : "_token"
},
"aggs": {
"nodes" : {
"terms" : { "field" : "_host" }
}
}
}
}
}'
{
"took" : 23,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"hits" : {
"total" : 2000,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"tokens" : {
"buckets" : [ {
"key" : "(-9223372036854775807,-4215073831085397715]",
"from" : -9223372036854775807,
"from_as_string" : "-9223372036854775807",
"to" : -4215073831085397715,
"to_as_string" : "-4215073831085397715",
"doc_count" : 562,
"nodes" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ {
"key" : "528b78d3-fae9-49ae-969a-96668566f1c3",
"doc_count" : 281
}, {
"key" : "7f0b782e-5b75-409b-85e9-f5f96a75a7dc",
"doc_count" : 281
} ]
}
}, {
"key" : "(-4215073831085397714,7919694572960951318]",
"from" : -4215073831085397714,
"from_as_string" : "-4215073831085397714",
"to" : 7919694572960951318,
"to_as_string" : "7919694572960951318",
"doc_count" : 1268,
"nodes" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ {
"key" : "528b78d3-fae9-49ae-969a-96668566f1c3",
"doc_count" : 634
}, {
"key" : "7f0b782e-5b75-409b-85e9-f5f96a75a7dc",
"doc_count" : 634
} ]
}
}, {
"key" : "(7919694572960951319,9223372036854775807]",
"from" : 7919694572960951319,
"from_as_string" : "7919694572960951319",
"to" : 9223372036854775807,
"to_as_string" : "9223372036854775807",
"doc_count" : 170,
"nodes" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ {
"key" : "528b78d3-fae9-49ae-969a-96668566f1c3",
"doc_count" : 85
}, {
"key" : "7f0b782e-5b75-409b-85e9-f5f96a75a7dc",
"doc_count" : 85
} ]
}
} ]
}
}
}
The same document count for all replica of a token range does not guarantee consistency between all replicas, but a different count allows to detect an inconsistency. Please note that according to your use case, you should add a filter to your query to ignore write operations occurring during the check.